
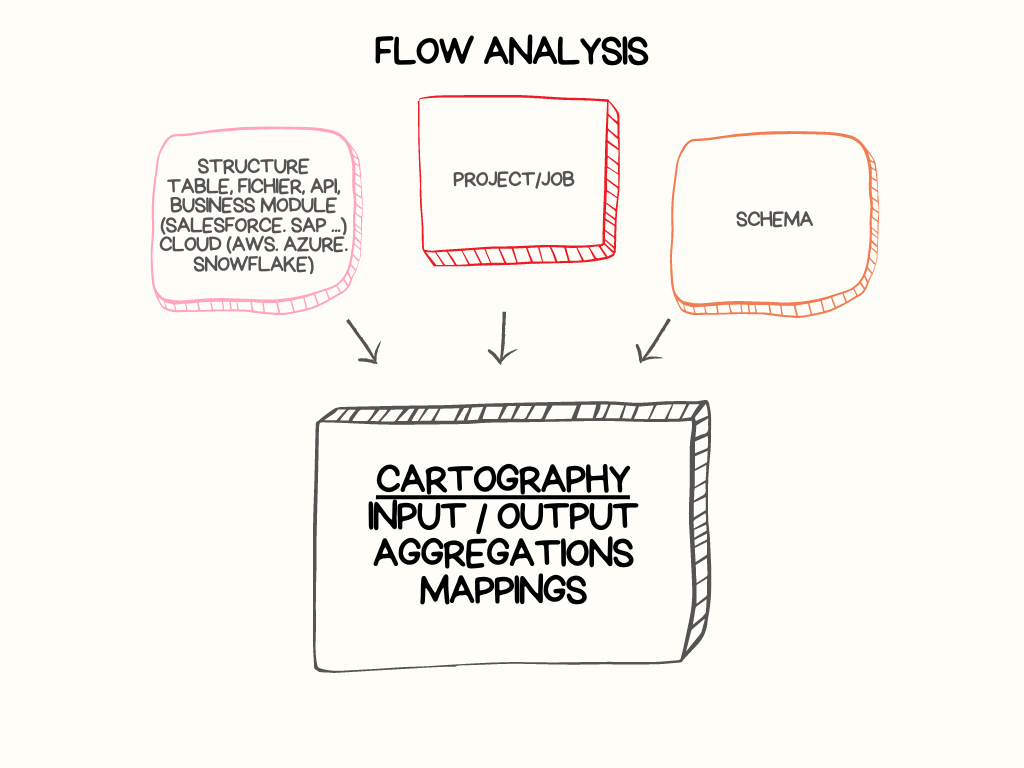
Data flow analysis enables searches based on the data structure. The search is focused on the usage of fields in components, jobs, and projects.
The analysis consists of three modules:
- Input/Output :
This module allows for analysis of the inputs and outputs of jobs. It focuses on the structures that enable querying data from a source and injecting data into a target.
- Aggregation :
This module enables analysis of field usage in the aggregations performed by the tAggregateRow and tAggregateSortedRow components.
- Mapping :
This module facilitates analysis of field usage in the tMap components.
The structures that can be found are listed in the table (Annex 2).
SQL queries are also analyzed to retrieve the tables and fields used in the tDBRow (Update, Insert, Delete, Merge) and tDBInput (Select) components.
| Composant | Sens | Element |
| tDbRow | Output | TABLE_UPDATE |
| tDBRow | Output | TABLE_INSERT |
| tDBRow | Output | TABLE_MERGE |
| tDBRow | Output | TABLE_DELETE |
| tDBRow | INput | TABLE |
Search mode
- Search by Project / Job / Job Prefix.

The search by Project / Job / Job Prefix allows narrowing down the search scope to focus on a specific project or set of projects, a job or set of jobs, or by applying a job prefix.
- Input / Output
The search can be performed by combining the field, the structure (Elements), and the name of the structure (Value elements).
- Aggregation
The search can be performed by combining the field name and the name of the function used.
The list of functions used is :
- GROUPBY
- min
- max
- sum
- avg
- first
- last
- Mapping
The search is performed at the level of input fields or output fields of the tMap.